
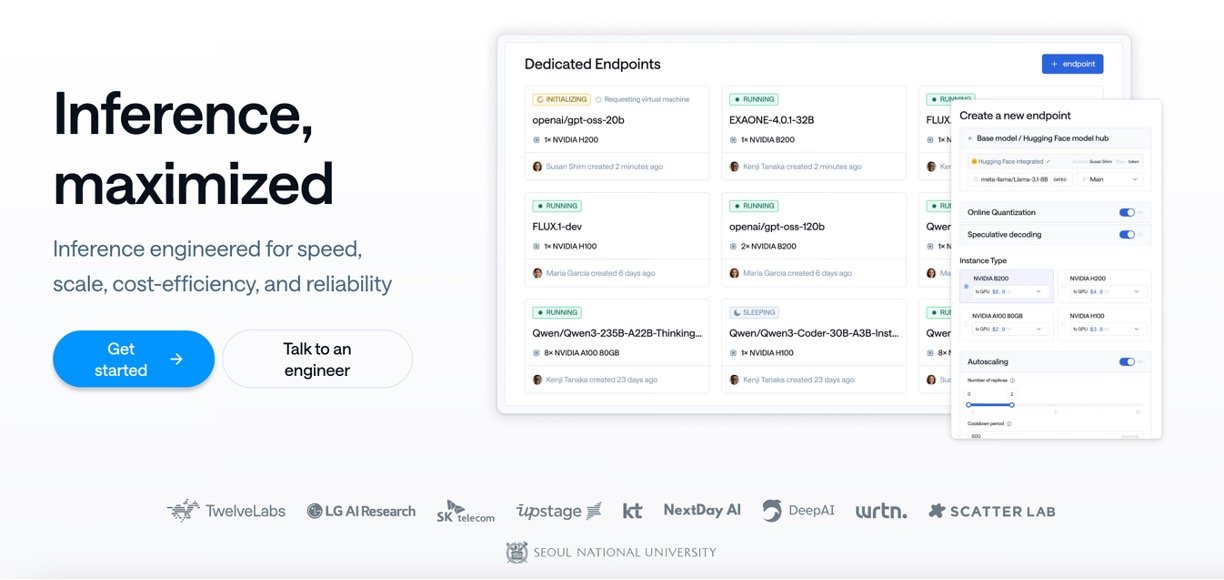
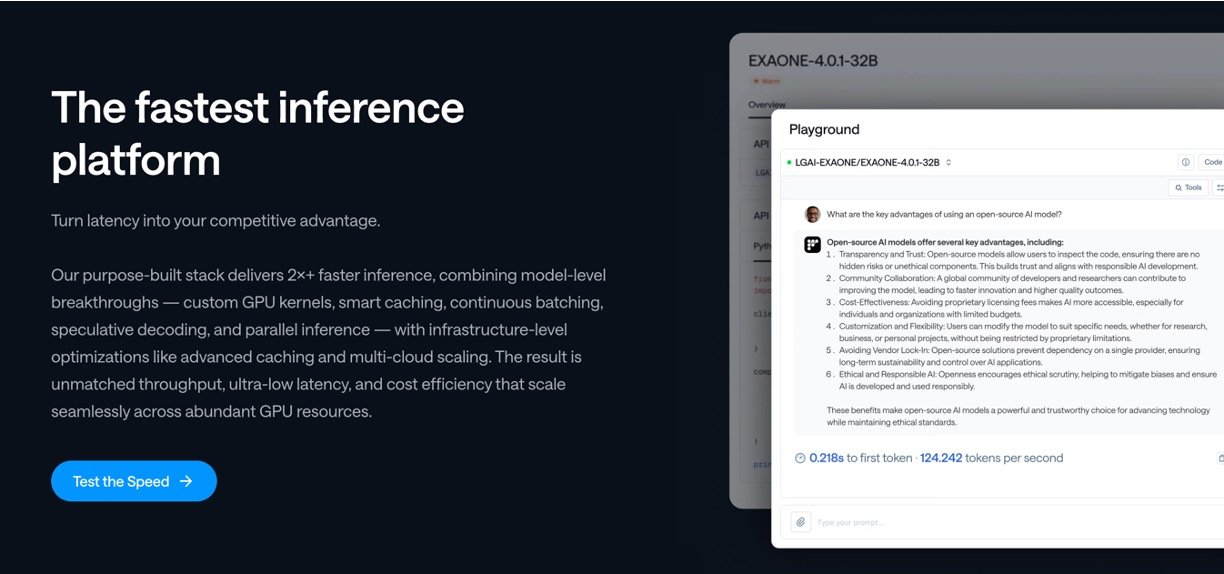
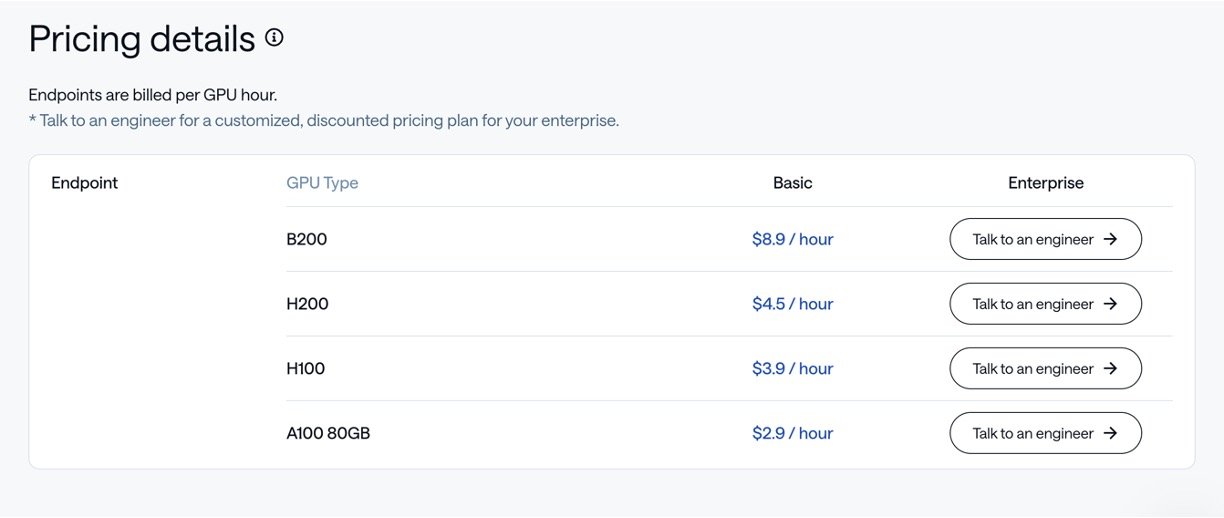
- Website
- Bookmark
- Share
- Claim listing
- Report
- prev
- next
{kind=link}
{kind=link}
You May Also Be Interested In
WebAI
- Run AI on Your Own Devices.
LLM
Paid
Union AI
- Scale without the crash.
LLM
Paid
Labelbox
- Build breakthrough AI with precision-labeled data at scale!
LLM
Paid, Free Trial