
- Website
- Bookmark
- Share
- Leave a review
- Claim listing
- Report
- prev
- next
Description
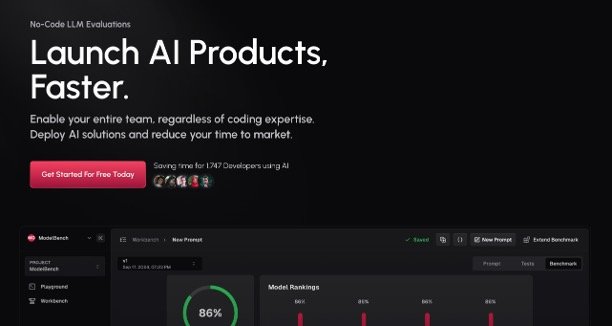
ModelBench.ai is a no-code platform designed to streamline the evaluation and comparison of over 180 large language models (LLMs). It empowers teams—including developers, product managers, and prompt engineers—to optimize prompts, benchmark models, and trace outputs without the need for coding expertise. By facilitating side-by-side model comparisons and providing tools for prompt engineering and benchmarking, ModelBench.ai accelerates AI development and testing processes, enhancing efficiency and collaboration within teams.
Key Features
- Extensive Model Comparison: Evaluate and compare responses from over 180 LLMs simultaneously to identify the best fit for specific use cases.
- Prompt Engineering Tools: Refine prompts with immediate feedback from multiple models, aiding in the development of effective AI interactions.
- Comprehensive Benchmarking: Create, run, and analyze benchmarks across various scenarios and models to ensure robustness and reliability.
- Trace and Replay Functionality: Monitor and analyze LLM interactions with the ability to trace and replay runs, facilitating the detection of low-quality responses.
Use Cases
- AI Model Evaluation: Assess multiple language models to determine the most suitable for specific applications.
- Prompt Optimization: Test and refine prompts to enhance AI model performance and response quality.
- Collaborative Development: Enable teams to work together seamlessly in developing and testing AI solutions without coding barriers.
Technical Specifications
- Platform Accessibility: Web-based interface accessible without the need for coding skills.
- Integration Capabilities: Supports integration with tools like Google Sheets for dynamic input management.
- Deployment Options: Offers both no-code and low-code integrations, with features like tracing and replay available in private beta.
Gallery


AI Agents Category
Reviews
Add a review
You May Also Be Interested In
Manus 
From thought to done—an AI assistant that actually acts
$
Paid
Operator
Let Operator handle the clicks—your digital tasks, automated
$
Free Trial, Paid
Flowith
Infinite AI agents that work 24/7.
$
Freemium